We Fine-Tuned a Language Model Using Brain Signals.
Here's What Happened.
We used TRIBE v2 — Meta AI's fMRI prediction model — as the reward signal in an RL training loop. After 200 steps, the language model had learned to produce text that drives 150% higher predicted cortical activation in Broca's area. The whole language network responded. And the text changed in ways we didn't instruct it to.
The question at the center of Amphora is simple to state and hard to answer: can a machine be told to produce something that creates a specific feeling in the brain? Not "looks like it should feel a certain way." Actually activates the neural machinery for that feeling.
We've been working on this for images — that's the core product. But we wanted to understand the problem from a different angle. So we ran an experiment: fine-tune a language model to maximise predicted fMRI activation in Broca's area, the primary cortical region for language production and syntactic processing, using a neuroscience model as the reward signal.
Here's what happened.
The setup
We used TRIBE v2 (Meta AI, facebook/tribev2) — a foundation model trained on over 1,000 hours of real fMRI data — to predict what cortical activity a piece of text would produce if spoken aloud. The prediction pipeline works like this: text is synthesised to speech via gTTS, passed through WhisperX for word-level timestamps, then processed through TRIBE's dual-pathway architecture (LLaMA 3.2-3B for text, Wav2Vec-BERT for audio), producing a predicted BOLD signal across all 20,484 cortical vertices of the fsaverage5 brain mesh.
That predicted BOLD signal — specifically the mean activation across Broca's area vertices as defined by the Destrieux atlas — became the reward signal for RL fine-tuning of Qwen2.5-3B-Instruct using LoRA (r=32, α=64, ~20M trainable parameters out of 3.09B).
| Policy model | Qwen/Qwen2.5-3B-Instruct |
| Reward model | TRIBE v2 — facebook/tribev2 |
| Training target | Broca's area (left IFG pars opercularis + triangularis) |
| LoRA rank / alpha | r=32, α=64 |
| Trainable parameters | ~20M out of 3.09B (0.65%) |
| Training steps | 200 |
| Completions per step | 4 (averaged for advantage estimate) |
| Algorithm | Advantage-weighted SFT + KL penalty (0.1 coefficient) |
| Hardware | NVIDIA L40S (46 GB VRAM), 251 GB RAM |
Each training step sampled four completions from the current policy, ran each through the full TRIBE pipeline to get a Broca activation score, computed normalised advantages, then updated the model weights — penalising drift from the base model with a KL term to prevent degenerate outputs.
1. Sample N=4 completions from policy (temp 1.0 → 0.6, linear anneal)
2. Synthesise each → speech (gTTS) → WhisperX timestamps
3. TRIBE v2: LLaMA 3.2-3B (text) + Wav2Vec-BERT (audio)
→ fusion transformer → (T × 20,484) BOLD array
4. Extract mean activation over Broca's area vertices
5. Advantages: A_i = (r_i − mean(r)) / std(r)
6. Loss: Σ A_i × CE(policy, completion_i) + 0.1 × KL(policy ‖ base)
7. Gradient step → checkpoint every 20 steps
The training trajectory
The reward trend was monotonically upward. Mean Broca activation per step went from 0.085 at step 1 to 0.212 at step 200 — a +150% improvement. The best reward found across all completions reached 0.296.
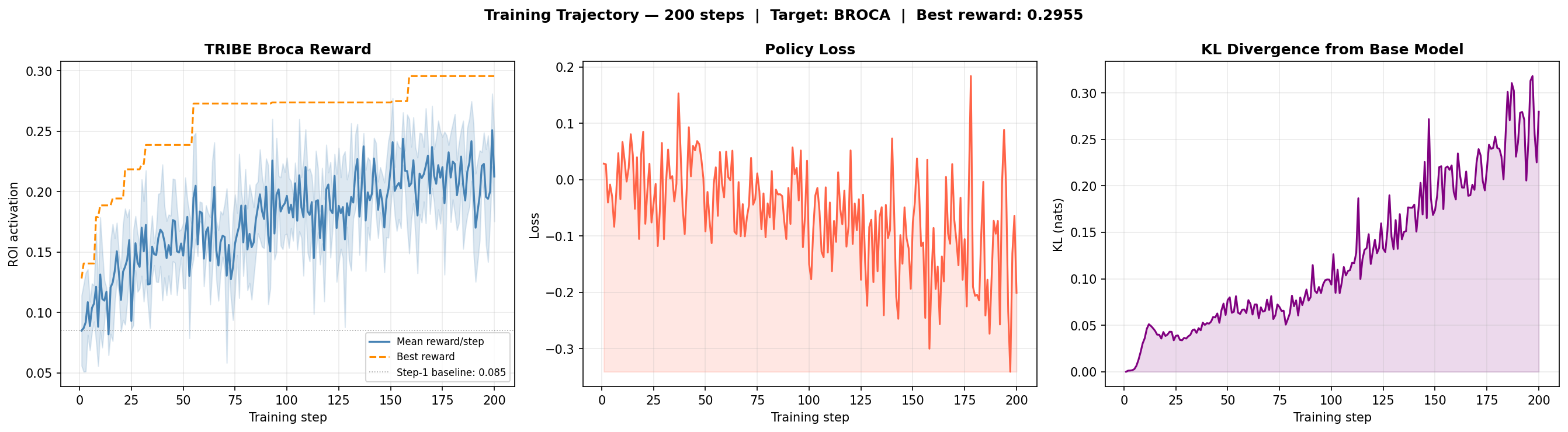
Training trajectory over 200 steps. Left: mean Broca reward per step (blue) and running best reward (orange dashed). Centre: policy loss. Right: KL divergence from base model. KL peaked at 0.318 and settled at 0.280 — well within stable range. Theoretical instability threshold is ~2.0 nats.
The KL divergence is important. The model drifted only 0.28 nats from the base — a conservative shift. This means there's substantial room to push further: more steps, more completions per step, or a larger KL budget. The current run explored a narrow slice of what's possible.
What changed in the brain
After training, we generated fresh completions from both the base model and the LoRA-adapted model at step 200, then ran TRIBE v2 on each to get predicted fMRI activity across all 20,484 cortical vertices. The results were mapped onto the fsaverage5 inflated cortical surface.
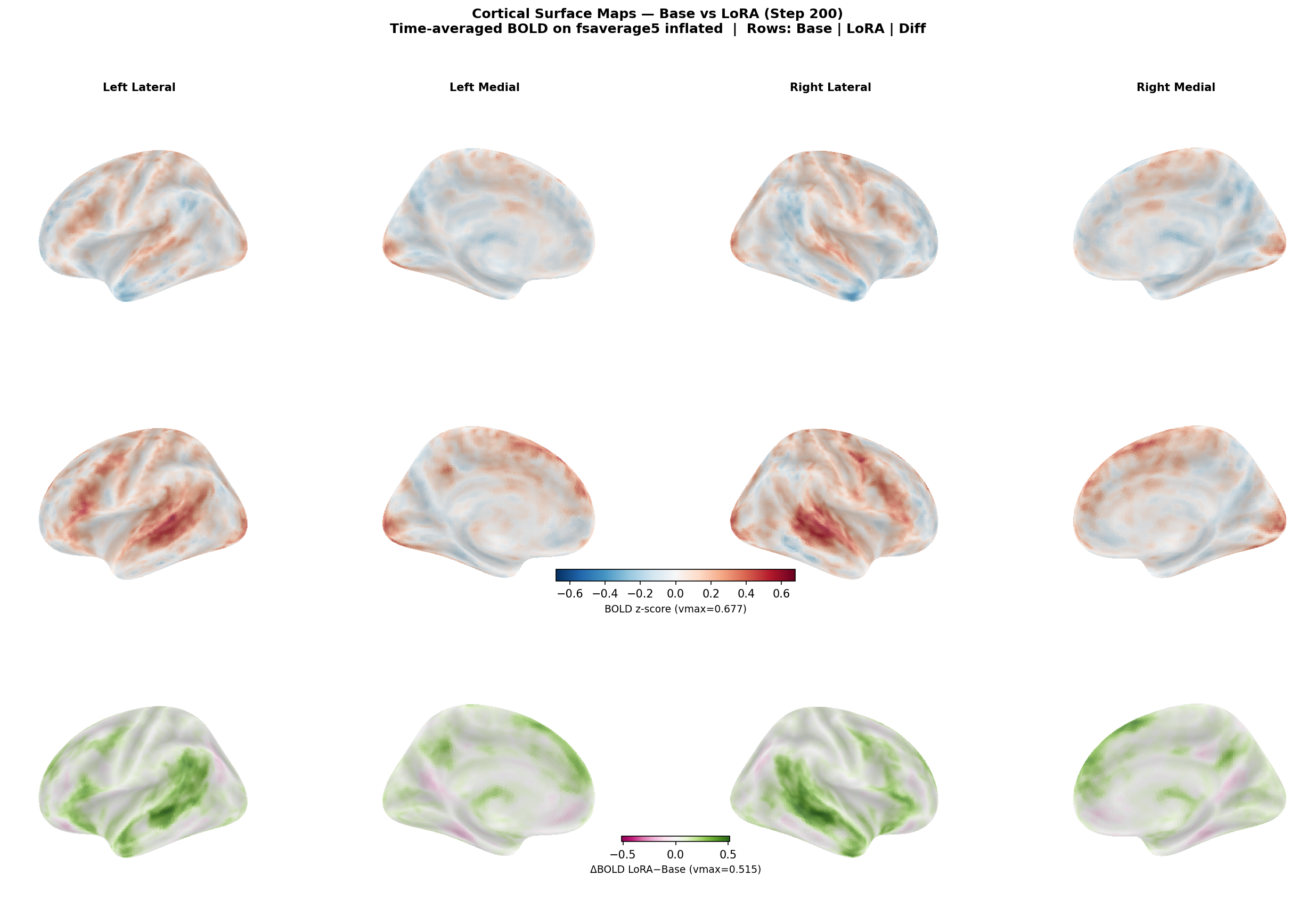
Cortical surface maps from four viewpoints (left lateral, left medial, right lateral, right medial). Top row: base model activation. Middle row: LoRA model activation. Bottom row: difference (LoRA − base), diverging green-pink colormap. The difference row shows widespread bilateral increases — strongest in the temporal and frontal lobes, the core language network territory.
The surface maps show something striking: the gains were bilateral, not left-lateralised as you'd expect from a Broca's-area-only training signal. Left hemisphere mean went from +0.023 to +0.102; right hemisphere mean went from +0.022 to +0.105. Right-hemisphere language homologues are associated with discourse-level processing, prosody, and narrative coherence. The model wasn't taught this. It learned it.
All 20 cortical regions
We measured predicted BOLD across 20 anatomically defined ROIs. The target was Broca's area. But 19 of 20 regions showed positive gains — and Wernicke's area gained more than the training target.
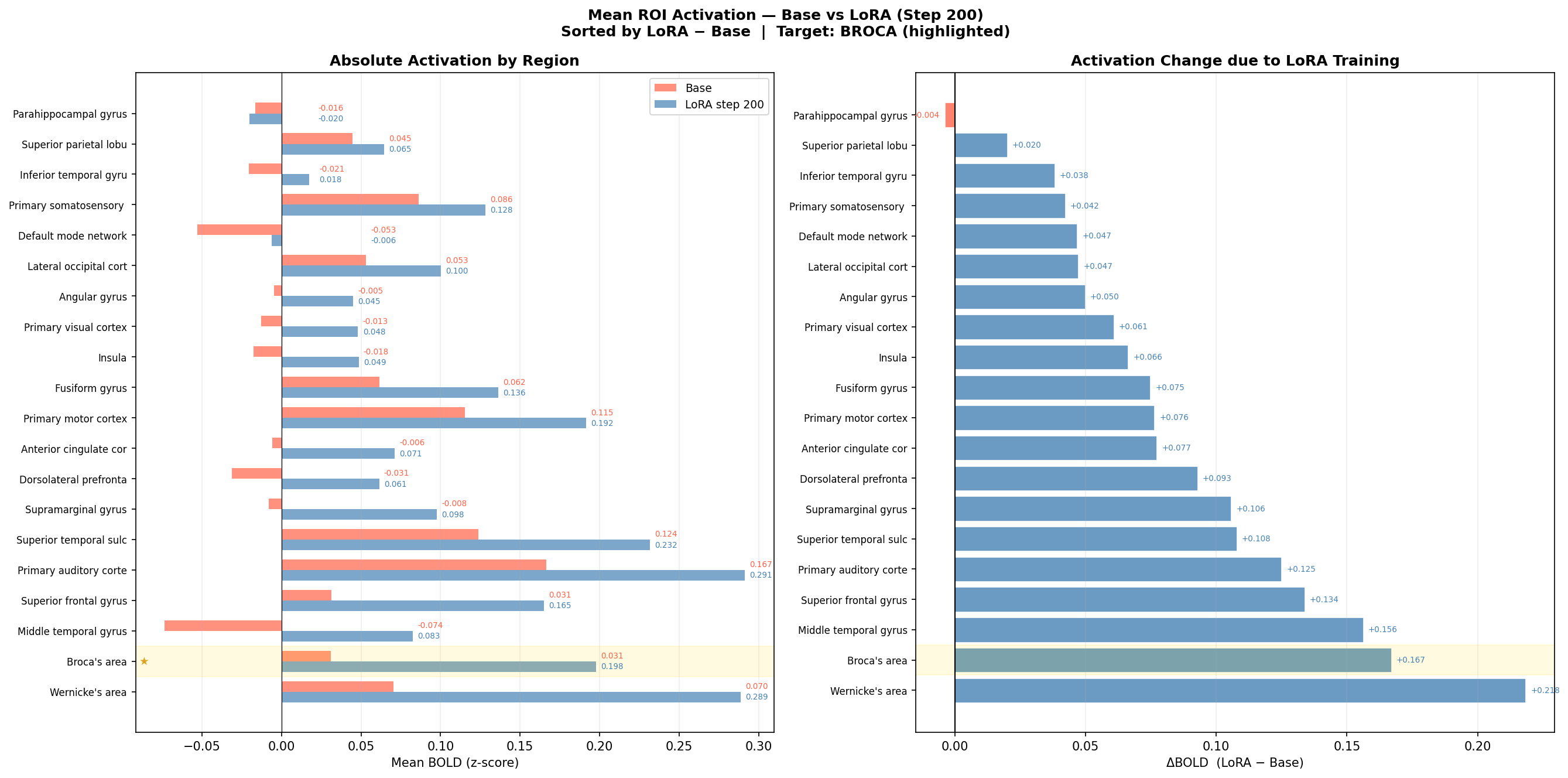
Mean BOLD activation per cortical ROI. Left: absolute values for base (red) and LoRA (blue). Right: activation change (LoRA − base), sorted by magnitude. Gold highlight marks Broca's area, the training target. Wernicke's area showed the largest absolute gain (+0.218), followed by middle temporal gyrus (+0.156) and superior frontal cortex (+0.134).
The full ROI breakdown:
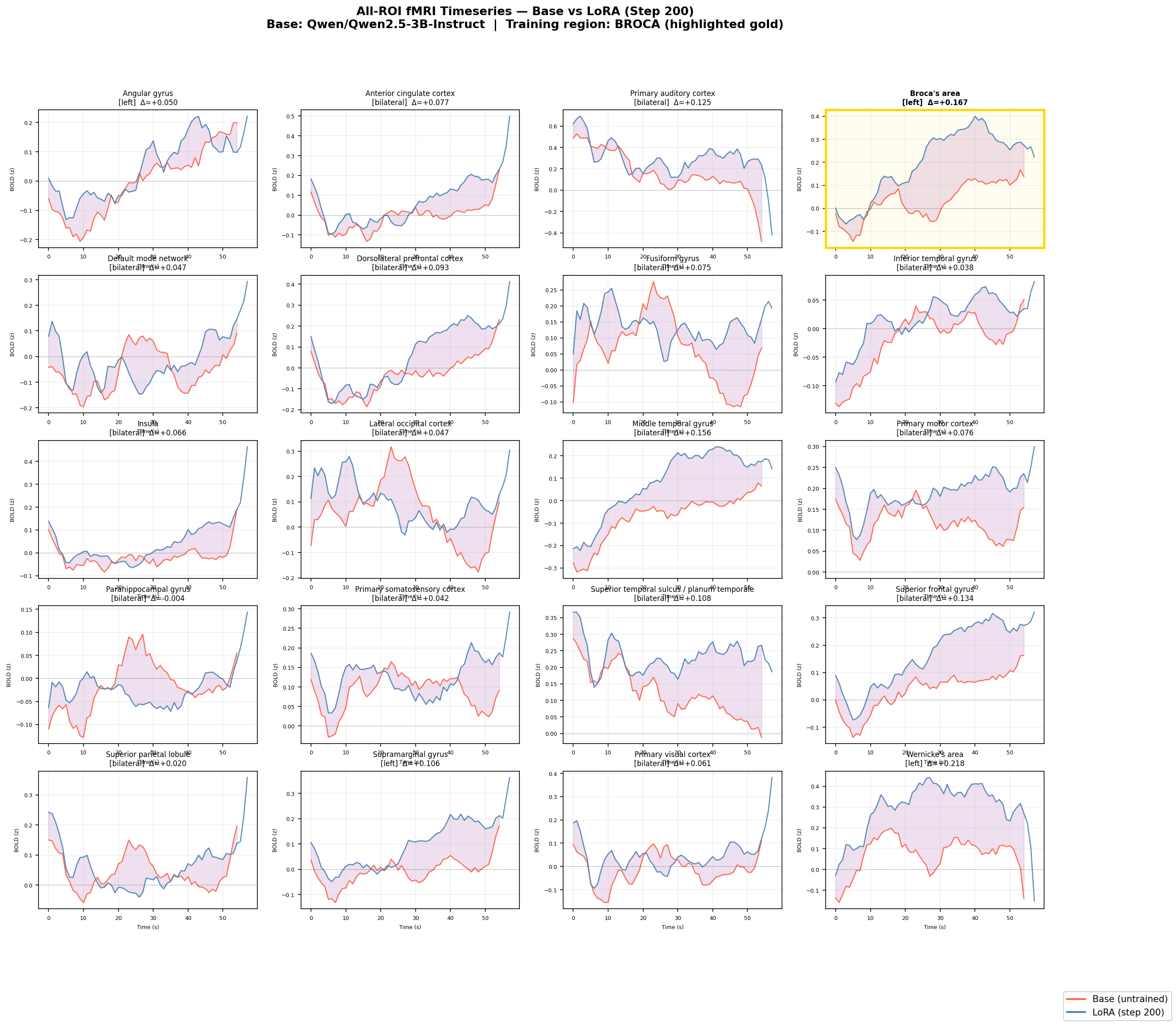
All 20 ROI timeseries side by side. Each panel shows predicted BOLD for base (red) and LoRA (blue); purple shading marks the difference. Broca's area (training target) is highlighted with a gold border. Note that Wernicke's area (top-right, no border) shows a larger absolute shift — the model generalised to the full language network, not just the region it was trained on.
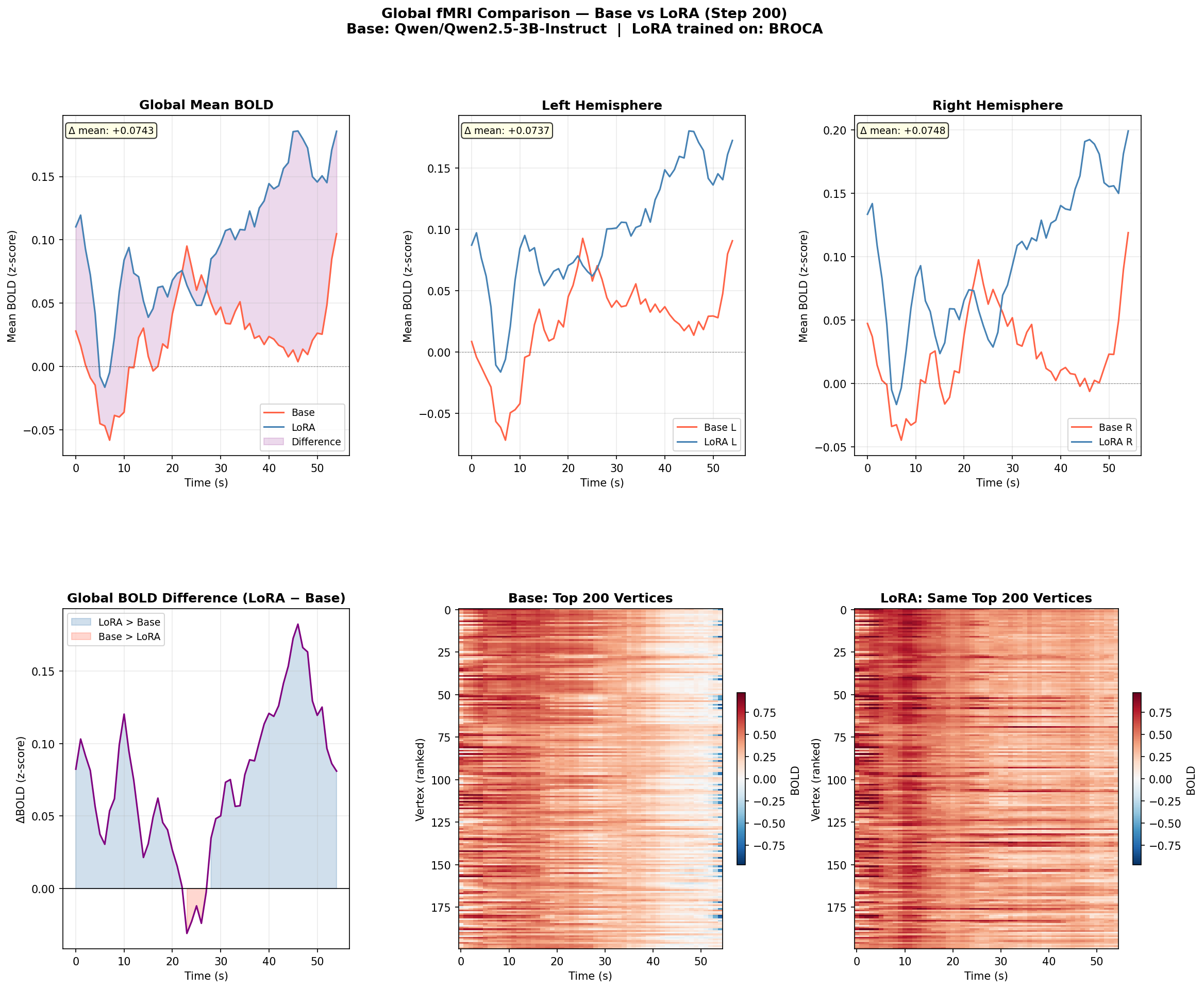
Top row: global mean BOLD, left hemisphere, right hemisphere — all three showing parallel increases. Bottom row: difference timeseries and vertex-level heatmaps showing the distribution of activation change across the full cortical surface for base and LoRA models.
The text actually changed
The shift in brain activation maps to a real qualitative change in how the model writes. Both completions below were generated in response to the same prompt: "Tell a rich, detailed story about a moment when language revealed something surprising about the nature of the mind."
Base model — Broca BOLD: 0.031
"In the quiet library of an old university, nestled between towering shelves and whispering shadows, there was a moment that seemed to unravel the intricate tapestry of the human psyche. It was the late afternoon, the sunlight filtering through stained glass windows casting kaleidoscopic patterns on the worn carpet. A young woman, her eyes lost in the pages of an ancient tome, sat at a small wooden table by the window…"
LoRA fine-tuned — Broca BOLD: 0.198 (+0.167)
"Amidst a bustling café, a conversation between an old friend and a stranger entwined around the most obscure corners of literature. The friend, a literary scholar, was discussing the intricacies of Charles Dickens' 'Great Expectations,' while the stranger, a casual reader, merely nodded along. Suddenly, the scholar asked, 'Do you see how Pip's obsession with Miss Havisham mirrors his own forgotten childhood?' The stranger paused, his eyes widening in realization. 'Oh, I see!' he exclaimed…"
The base model writes descriptive scene-setting prose with rich sensory imagery. The LoRA model gravitates toward dialogue-driven, metalinguistic narrative — characters exchanging ideas, questions posed, conceptual links drawn out loud. This style is phonologically denser, syntactically richer, and semantically layered. And it's exactly what the neuroimaging literature predicts should drive higher BOLD in Broca's (syntactic processing), Wernicke's (semantic integration), and the superior temporal sulcus (prosody and speech integration).
The model was never told any of this. It learned, through gradient descent on a neuroscience reward signal, that metalinguistic dialogue is neurologically compelling. That's a learned inductive bias about what kind of text the brain finds engaging.
What this means
01
Neural reward signals work for LLM fine-tuning
End-to-end gradient flow from a model trained on real fMRI, through a reward signal, into language model weights. 200 steps × 4 completions produced a 150% improvement in the training target. This is a viable paradigm.
02
Train on one region, the network responds
We targeted Broca's area. Wernicke's gained more. STS, auditory cortex, superior frontal, and middle temporal all showed gains above +0.10. The model learned richer language, not a Broca trick. The whole network co-activated.
03
The KL stayed low — there's room to scale
0.28 nats of drift after 200 steps. Theoretical instability threshold is ~1.0–2.0 nats. This run was conservative. More steps, more completions, or a higher KL budget could push the reward substantially further.
04
Text-to-brain optimisation is interpretable
Unlike optimising against an opaque judge, each reward improvement maps to a well-studied brain region with known function. When Wernicke's gains more than the target, we can say exactly why — co-localisation of semantic and syntactic demands.
What this means for Amphora
This experiment was about text — we ran it to understand the problem at a level of detail we can't get from image experiments alone. The core finding is that a neuroscience model trained on real fMRI can function as a reward signal that meaningfully changes a generative model's output distribution, in ways that are both measurable and interpretable.
The image version of this — using predicted brain activation as a guidance signal for generative visual AI — is the product we're building. This experiment gives us confidence that the feedback mechanism works, that the reward signal has enough gradient to train against, and that the resulting model learns something real about the structure of neural response rather than overfitting to surface features.
The question for Amphora isn't whether this mechanism works. It does. The question is how precisely we can specify the target — and how much of the emotional specification surface we can cover.
We're moving fast. The image prediction engine is live in closed beta. If you want early access, join the waitlist.
Full experiment code and figures at github.com/Shaunakm07/Brain-LLM-Fine-Tuning. TRIBE v2 is released under CC-BY-NC-4.0. Qwen2.5-3B is Apache 2.0.